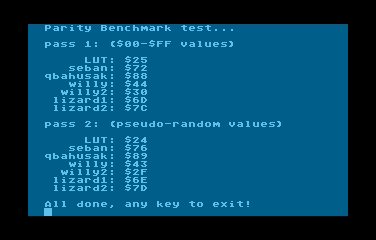
No to mamy nowego króla wydajności (pomijając LUT na który trzeba zmarnować 256 bajtów pamięci :P)
ja metodę xor-based znałem ze świata HDL-owego (dlatego pisałem o tym że HDL-owo się zrobiło jak ją Willy zaprezentował), tzn. stosowałem ją np. w kodzie verilogowym dla SlightSID-a, tyle że w verilogu to jeszcze prościej, w przypadku rej. konfiguracyjnego SlightSID-a musi się zgadzać parzystość danych, tylko wtedy rej konf. będzie "zaktualizowany":
inout [7:0] ata_DAT; // ATARI data bus
...
...
if (atr_str[7:0]==8'h41 && ~(^ata_DAT)) cfg_reg <= ata_DAT;
a więc jak widać całe "obliczenie" parzystości sprowadza się do wykonania operacji XOR na wszystkich bitach i zanegowaniu wyniku:
I to jest własnie piękno "języków opisu sprzętu!" :D
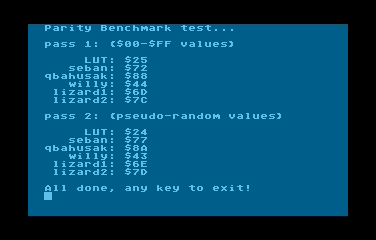
W sumie po tych moich przygodach z parzystością na początku lat '90 nigdy potem nie miałem potrzeby obliczania parzystości na 6502 i zaprezentowałem te moje wykopalisko z przeszłości bez większego zastanawiania się nad problemem, nawet nie chodziło mi o żaden wyścig na cykle, a temat potraktowałem jako ciekawostkę, która koniec końców dzięki waszym postom przekształciła się całkiem ciekawy wątek. W dodatku QbaHusak zainspirował mnie to optymalizacji i napisania tego mini-bechmarka, wiem że nie jest on doskonały ani jakiś "pro", ale mniej więcej spełnia swoje zadanie pozwalając zweryfikować czy każda z procedur działa poprawnie i ile czasu się wykonuje.
Ostatni kod zaprezentowany przez Willy-iego (ten z 6502.org) pokazuje jak bardzo ekstremalnie można zoptymalizować każdy problem! :) To się nazywa pomysłowe wykorzystanie dostępnych instrukcji CPU aby osiągnąć efekt końcowy :D Ten fragment kodu w zestawieniu z verilogową implementacją bardzo fajnie pokazuje jak rozbić problem natury typowo równoległej na coś co da się wykonać etapami, i co ciekawe nie krok po kroku (metodą zliczania poszczególnych jedynek) ale jak wykorzystać możliwości prymitywnego ALU którym dysponuje 6502 do "zrównoleglenia" operacji.
@marok: dzięki za miłe słowa, jednak uważam że nie robię nic wyjątkowego, a to że czasami mi coś wyjdzie można chyba tłumaczyć tylko tym że jak mnie jakaś rzecz zainteresuje to staram się poznać dany temat jak najlepiej, czy też na tyle na ile pozwala moja możliwość percepcji. Sądzę że inni są o wiele bardziej sprawni w różnych kwestiach. Dla mnie niektóre rzeczy są po prostu poza zasięgiem bo wymagają jakiegoś mega abstrakcyjnego myślenia, co w moim przypadku jest chyba jakimś problemem... mój mózg działa chyba w ten sposób że wszystko dla niego musi być logiczne i wytłumaczalne w prosty sposób, jeżeli problem jest natury abstrakcyjnej trudno zainteresować moją mózgownicę tego rodzaju problemami, tak już mam i nic na to nie poradzę :D